這是 MySQL5.6 之後才出現的,是一種根據索引進行查詢的優化方式,其運作原理是: 當有一個 SQL 語法用到索引的時候,在查找索引的過程中"順便"過濾 where 條件,進而提升資料庫的整體性能。
好吧,我相信只看上面這句話應該是很難理解。後面再舉個例子來說明。
先舉一個例子來說明
測試資料
有一個複合索引 (num, uname)
CREATE TABLE tb1 (
id int not null auto_increment,
num int,
uname varchar(20),
phone varchar(10),
PRIMARY KEY(id),
KEY(num, uname)
);
INSERT INTO tb1(num, uname, phone) values
(11,'Kobe Bryant','0912345678'),
(12,'Michael jordan','0912876543'),
(13,'Stephen curry','0912111111'),
(14,'Lebron james ','0912222222'),
(15,'James harden','0912333333');
SELECT * FROM tb1 WHERE num = 14 and uname like '%james%'
*圖1 *
從圖1可以看到 Extra 欄位出現 : Using index condition。
表示優化器選擇使用 ICP。
在沒有ICP之前,這個 SELECT 只會用到 num 這個索引定位到 num = 14,將資料取出後再去過濾 uname 這個欄位。因為 uname like '%james%' 是無法使用索引的。
但是如果有啟用 ICP,在定位到 num =14 的時後就直接進行 uname 的過濾,滿足的話才取出資料。不過前提是 uname 也要在這個複合索引裡面。
簡單來說 ICP 就是查詢時有一部分無法直接使用索引,這裡就是指 uname 這個欄位。
※ 這裡可能會有點疑問,有沒有啟用ICP 感覺差別在於一個是取出 num=14 後再去過濾,一個是定位到 num=14 就順便過濾?差在哪?
這裡我覺得有一個網站畫的圖蠻清楚的,分享過來給大家參考一下
★ 如果沒有用ICP
--> 會到存儲引擎層把符合索引(num=14) 的取出返回 server 層,在透過 where 去過濾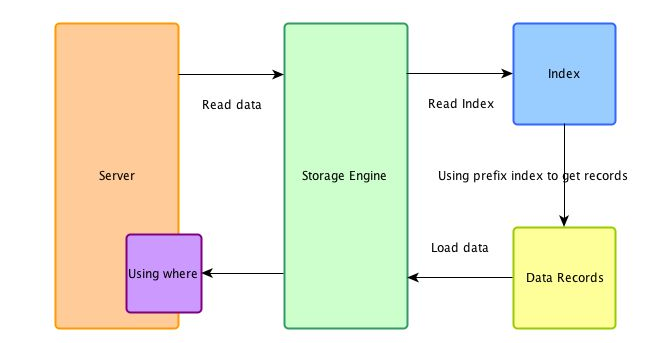
圖2 參考至 一起学习Mysql索引三(ICP,索引条件下推)
★ 如果有啟用ICP
--> 就可以利用複合索引中的 uname 這個欄位,當定位到 num=14 在看看是否滿足 uname,滿足的話就取出。也就是說 server 層把工作下推到存儲引擎層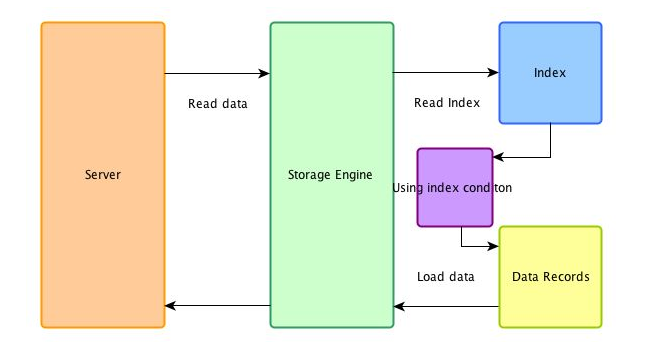
圖3 參考至 一起学习Mysql索引三(ICP,索引条件下推)
透過 ICP ,總之就是減少了 server 層的操作,因為下推到引擎層去處理了。
另外有一些限制
SELECT id,num,uname FROM tb1 WHERE num = 14 and uname like '%james%'
這句因為 id,num,uname 在輔助索引中就可以取得,所以不須要回到叢集索引,
因為用了覆蓋索引,所以不用ICP優化了。
資料庫知識相當廣泛,文中若有不正確的地方,也煩請各位大神不吝指教,謝謝
參考網站
一起学习Mysql索引三(ICP,索引条件下推)
MySQL原理与实践(一):一条select语句引出Server层和存储引擎层
 Stock
Stock

